When designing communication structures between processes, many products and methodologies focus on embedding intelligence directly into the communication mechanism. A notable example is the Enterprise Service Bus (ESB), which often includes sophisticated capabilities for message routing, choreography, transformation, and the application of business rules.
In contrast, the microservices community champions a different philosophy: smart endpoints dumb pipes. In microservices-based applications, components are intentionally designed to be highly decoupled and cohesive, managing their own domain logic. They operate similarly to Unix filters—receiving requests, processing them, and generating responses. Communication between these services typically relies on straightforward protocols like REST or event-driven systems.
However, just as Unix filters need to be chained together, microservices must interact and share data to meet the overall requirements of a product. While microservices are independent by design, they cannot function in isolation. To enable communication, two primary approaches exist: orchestration and choreography. Both aim to facilitate inter-service communication but do so in distinct ways. ThoughtWorks, the company credited with popularizing microservices, strongly advocates for choreography as the preferred approach. To quote:
The microservice community favours an alternative approach: smart endpoints and dumb pipes. Applications built from microservices aim to be as decoupled and as cohesive as possible – they own their own domain logic and act more as filters in the classical Unix sense – receiving a request, applying logic as appropriate and producing a response. These are choreographed using simple RESTish protocols rather than complex protocols such as WS-Choreography or BPEL or orchestration by a central tool.
This means that in a choreographed system, each microservice inherently knows which other services it needs to communicate with and how to exchange data. These interactions are typically managed using simple, event-driven or REST-like protocols. Let’s take a look at the graph:
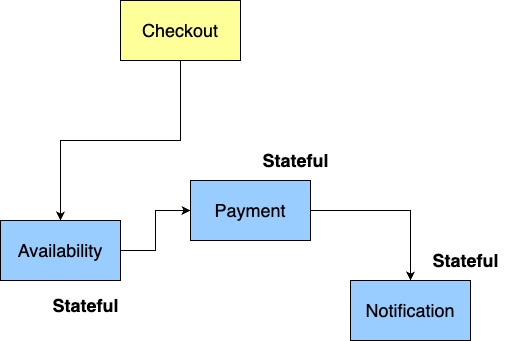
* Stateful/Stateless naming refers to knowledge about the state of the process. It does not refer to wherever the service is storing its own data.
As you can see, there is no central authority directing the flow of traffic; each microservice knows its next step in the process. In our reservation system example, after proceeding to checkout, the system checks service availability. If available, it moves on to payment, and upon successful payment, the client is notified that the reservation was made. While this architecture is widely used, it has a significant drawback: over time, it can become highly complex. During development, I often encounter systems with thousands of interconnections, which undermines one of the key advantages of microservices—independent deployment.
On the other hand, we have orchestration. Orchestration involves a central controller that manages the entire process, utilizing various services and delegating tasks while maintaining full control. Let’s visualize it:
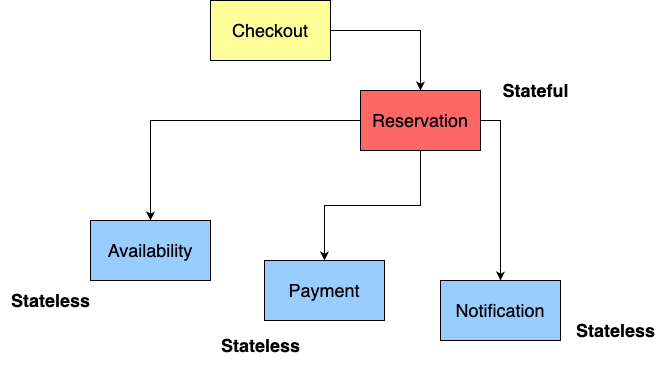
In the graph, the Reservation service (acting as the orchestrator) has complete control over the reservation process. It determines the order in which downstream microservices should be called, handles error responses, and manages fallback strategies. This setup creates what is often referred to as a ‘god process,’ analogous to the ‘god class’ antipattern at the code level. It closely resembles the behaviour of an Enterprise Service Bus (ESB), which has been criticized by Martin Fowler in his ThoughtWorks article. But why is this architecture considered problematic?
- Firstly, it causes business logic to leak from microservices into higher-level components like the orchestrator (often named Leaking abstraction). For example, it’s no longer the Payment service that decides what to do if a payment fails (such as switching from bank transfer to mobile payment or retrying the payment process). Instead, the Reservation service dictates the response.
- Secondly, this approach makes the services ‘dumb.’ They become mere containers for data, with the real logic and decision-making moved to higher-level components.
- Moreover, if the payment strategy needs to be updated, you don’t just modify the Payment service. Instead, you have to make changes across multiple orchestrator processes that interact with it. Why multiple? Because we may have multiple orchestrators that interacts with this Payment service (not shown in the diagram)
We’ve examined two approaches, each with its own set of criticisms. So, what’s the next step? Is there a more effective solution that addresses the shortcomings of these strategies? Indeed, there is. Let’s explore it:
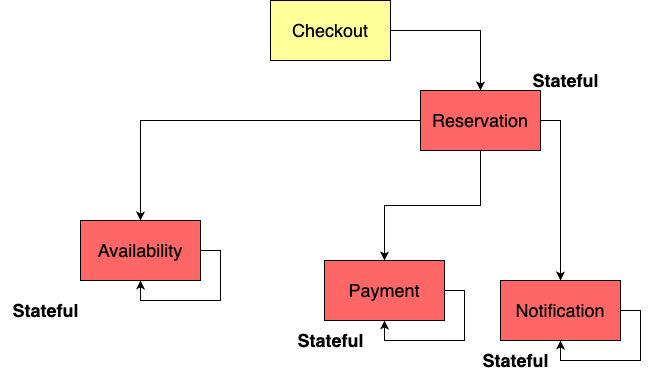
This graph resembles the orchestration strategy but with a key difference in statefulness. While we still have a central orchestrator serving as the ‘glue’ between microservices—managing the sequence of invocations, such as checking availability, processing payment, and sending notifications—each service now manages its own internal logic independently.
In this model, the Reservation service no longer intervenes if there are issues within the Availability service. If the Payment service encounters a failure, it handles retries, switches payment strategies, or even defers payment without intervention from the orchestrator. This approach restores control of domain-specific logic to the respective services, leaving the orchestrator to purely coordinate the process without being burdened with internal service details.
To quote ThoughtWorks
In a monolith, the components are executing in-process and communication between them is via either method invocation or function call. The biggest issue in changing a monolith into microservices lies in changing the communication pattern. A naive conversion from in-memory method calls to RPC leads to chatty communications which don’t perform well. Instead you need to replace the fine-grained communication with a coarser -grained approach.
Disclaimer
- The diagrams presented here are conceptual and are not tied to any specific communication protocol. Whether you use REST, SOAP, gRPC, or event-based systems like Kafka, the strategies discussed can be implemented across all these protocols and architectural styles. The chosen communication architecture style will impact the microservice temporal coupling level, CPU usage, and speed however it does not change a thing in the above strategies.
- In an ideal world, microservices should aim to make as little as possible REST API calls to other services. In practice, if system performance is a priority, microservice-to-microservice REST API calls should be avoided entirely. To achieve a robust microservice architecture, it’s essential to adopt a data locality paradigm, ensuring that each microservice has direct access to the data it needs without relying on external calls. This is the ideal state we strive for, but real-world challenges often necessitate adjustments. That’s why employing a well-designed orchestration strategy is crucial.