In the fast-evolving world of software development, microservices architecture has become the go-to solution for building scalable, resilient, and agile applications. However, the complexity of managing numerous independent services demands a robust Continuous Integration and Continuous Deployment (CI/CD) pipeline to ensure seamless integration, testing, and deployment. Getting CI/CD right for microservices is critical, as it directly impacts the efficiency and reliability of the development lifecycle. This blog post will explore best practices, tools, and strategies to implement an effective CI/CD pipeline for microservices, helping teams deliver high-quality software faster and more efficiently.
You should consider this post to be an extension for Testing done right post and Integration testing in AWS.
Let’s firstly look at the proposed CI/CD solution:
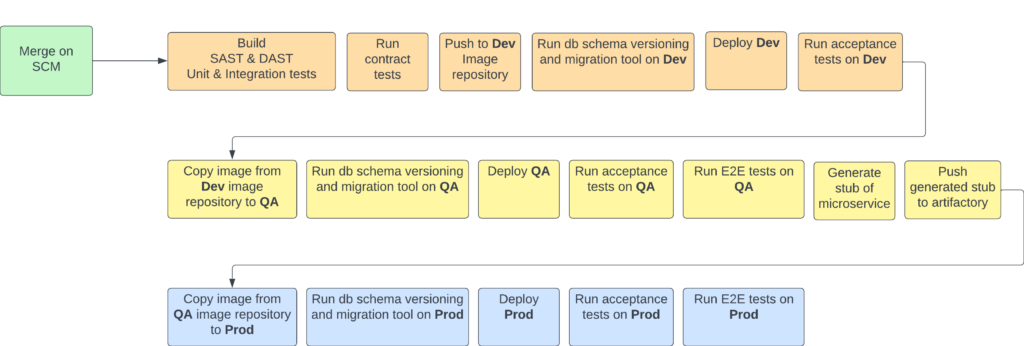
In microservice world, each merge to main branch of application repository should immediately trigger a microservice CI/CD pipeline to be started without any manual intervention. This pipeline ideally in continuous deployment should start from building microservice to test run in the production. In really critical situations we could follow continuous delivery principle, however this should be really justified by the importance of the project. Let’s take a look into each of the steps we have in bigger details
Build, SAST & DUST, Unit & Integration tests
All those action can happen inside one block since they are tightly connected with each other, since you can’t just run the build without application tests! This would make no sense. Tests should include every test cases that were designed to run locally without internet connection – i.e. unit and integration tests. SAST and DAST analysis is a prerequisite for further steps to comply with the company code standards.
Run contract tests
Contract tests should verify that all microservice integration contracts are preserved, regardless of whether we are using SOAP, REST, event-based communication, or any other protocol. These tests ensure that the interactions between services adhere to agreed-upon contracts. To achieve this, we should create comprehensive contract tests that validate all possible interactions, utilizing generated stubs of dependent services.
While contract tests are a complex topic deserving a separate blog post, it is crucial to emphasize their importance in the CI/CD pipeline. Properly implemented contract tests are essential for maintaining the integrity and reliability of microservices integration.
Push to Dev image repository
This is a no-brainer action. Once the initial layer of tests (unit, integration, and contract) pass, the build turns green, and SAST and DAST tools do not detect any code smells or bugs, we should proceed to push the prepared application as a Docker image.
Run db schema versioning migration tool on Dev
Microservices rarely operate in isolation. Most of them need to persist their state, typically not via file systems but through databases. For security reasons, it’s crucial that applications are not granted DDL (Data Definition Language) permissions. This is particularly important in enterprise applications to prevent attackers from performing destructive operations on the database if the application is compromised.
Instead, create a separate container image with a database migration tool like Liquibase or Flyway to handle these operations. Ideally, you should store the database migration tool’s Docker image definition and all necessary files within the application’s repository. This approach prevents SQL duplication and ensures consistency.
When running the application locally, you can configure it to use the auto-DDL creation files stored in the DB migration folder within the same Git repository. This setup maintains security while simplifying the management of database schema changes.
Deploy Dev
Simple deploy operation. Remember about remediation actions like detecting deployment failure and failover to previous application. From my perspective the best way to achieve it is via console tools like AWS CLI.
Run acceptance tests on Dev
This is a critical safety check that we should perform in the running environment. After passing unit, integration, and contract tests, the likelihood of failure due to application code issues is minimal. At this stage, the primary concerns are potential misconfigurations in the live environment, such as incorrect networking setups, wrong environment variables, or infrastructure problems. Essentially, the focus shifts from code issues to environment-specific issues.
To conduct this check, we can begin by testing basic scenarios on the application deployed to the live environment. It is important to note that at this level, we should only test simple happy and unhappy paths. Avoid creating any complex test scenarios. The goal is to have tests that send an API request, wait for the response, and validate the response—nothing more. We must remember that tests running outside local environments can significantly increase run time. Given that the pipeline may run multiple times a day, it’s crucial to keep this time at a reasonable level.
Copy image from Dev image repository to QA
This is quite important step that sometimes is not understood by company stakeholders. In many companies I see pattern of placing everything under one Image repository and pulling everything from central hub. While this works it can cause several problems during operations.
- First of all since this is a place from which all environments are pulling images it needs to be properly secured from manual access. This means that developer do not have a direct access to it. It creates many problems during day-to-day deployment activities (e.g. developers wanted to test something on dev environment).
- We are introducing big single point of failure. When main image repository will go down, than we stop not only production but also development efforts! As a golden rule – don’t place all your eggs in one basket
- You are coupling environments with each other. While some might argue that an image repository isn’t technically an environment, it is still tied to a specific account that the environment operates under!
Instead of this pattern you can create a image repository per environment and just copy the image from one to another! The downside of this approach is that image will become broken during a copy operation from QA to Prod environment, however this is a issue that I can sacrifice in order to persist environment separation. In the worst case scenario the pipeline will just failover to the previously deployed image!
Run db schema versioning migration tool on QA
Similar to “Run db schema versioning migration tool on Dev“
Deploy QA
Similar to “Deploy Dev“
Run acceptance tests on QA
Similar to “Run acceptance tests on Dev“
Run E2E test on QA
This step marks a clear distinction from the previous part. You might wonder why we run E2E tests here and not in the development environment. The answer is simple: because it’s the development environment. By definition, the development environment is not stable. It’s a space where developers can freely experiment with their code, isolated from other teams. There should be no SLA in development since it’s a playground for testing new features, making manual changes, and conducting proofs of concept.
As long as these actions are isolated from others (i.e., changes by one team do not affect another), we’re in an ideal situation. Such isolation can be achieved through various methods, such as Resource Groups in Azure or Accounts in AWS. Having separate AWS accounts doesn’t necessarily mean different teams can’t communicate. We can expose our private APIs via the Private Link functionality, which is highly supported in the AWS ecosystem.
Generate stub of microservice
After passing the end-to-end (E2E) tests, we have essentially completed the entire CI/CD pipeline across two environments. We have run every possible check, ensuring the deployment to production is just a formality. At this stage, we are confident that the application is fully functional after QA.
However, to allow other services to run contract tests against our application, we need to generate a stub. This stub will provide predefined responses for specific API endpoints, enabling other applications to conduct their tests in the same manner as we did during the “Run contract tests” stage in our pipeline.
Push generated stub to artifactory
After generating stub we need to push it to artifactory from with other teams can pull from
Copy image from QA image repository to Prod
Similar to “Deploy Copy image from Dev image repository to QA“
Run db schema versioning and migration tool on Prod
Similar to “Run db schema versioning and migration tool on Dev“
Deploy prod
Similar to “Deploy dev“
Run acceptance tests on Prod
Similar to “Run acceptance tests on Dev“
Run E2E test on Prod
Similar to “Run E2E test on QA“
And.. that’s it! Nothing more is needed to ensure our application stack running locally.
However there are some points that I want to highlight:
- At all costs keep environment’s separate. Dev/QA/Prod environments can’t know anything about each other!
- Implement team isolation rule in Dev. Changes done by Team A in Dev environment should have no impact on team B in Development environment!
- Each of those steps have its particular purpose. Removing any of them exposes you to the risk of omitting important check
Rollback on CI/CD
Note that pipeline presented in this blog does not contain rollbacks from particular steps. I didn’t added it there since I wanted to have a clear picture of the sole happy path of deployment. Let’s take a look at version with rollbacks
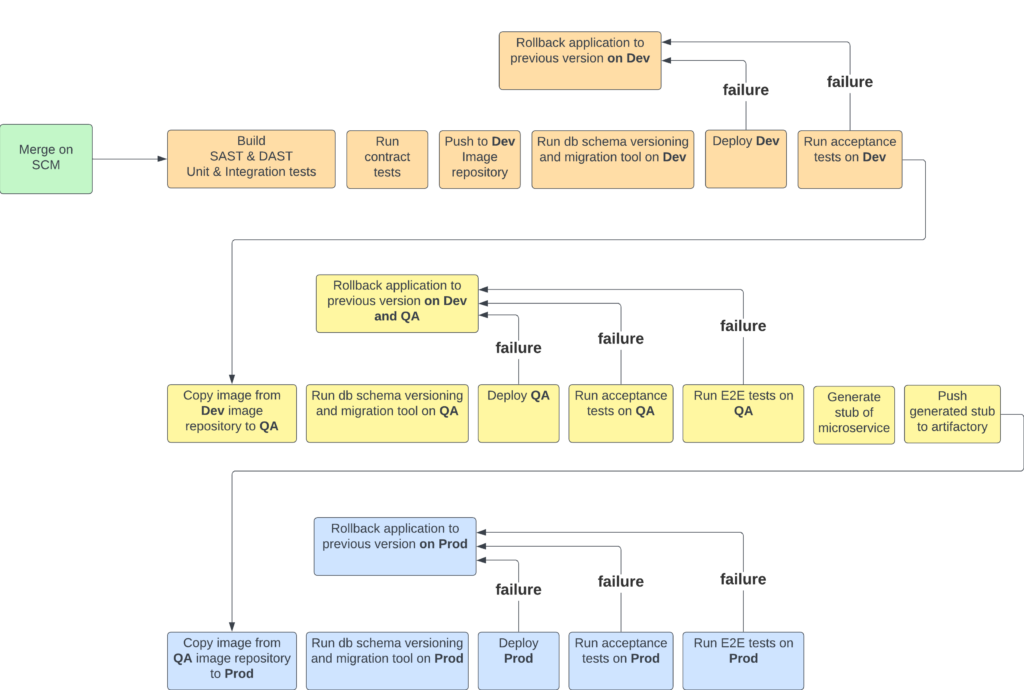
As you can see, the appropriate rollback actions depend on the stage at which our application fails.
- If the failure occurs during the Dev stage, we only need to roll back the Dev environment since we haven’t progressed further. This scenario accounts for 90% of the cases I’ve encountered. When tests are properly configured, they should catch up to 90% of all potential failures.
- If the failure happens in the QA stage, both Dev and QA environments need to be rolled back. QA needs to be rolled back because the environment is broken, and Dev needs to be rolled back to enable ongoing development for other developers. If deeper investigation is necessary, a developer can reprovision the failing application version independently.
- If the failure occurs in the Prod stage (which ideally should never happen), we only roll back production. This is because Dev and QA passed successfully, running the same set of tests, deployments, and scripts as Prod. A failure in production suggests that something is misconfigured specifically in that environment. Additionally, to facilitate a faster debugging process, rolling back QA and Dev would only prolong the time needed to investigate the problem.
You might also wonder why there are no rollbacks during database updates. The general rule here is that every database operation should be backward compatible. If this is the case, there’s no need to roll back even if the application deployment fails and a rollback occurs.